Project Enzian: A New Research Computer - Heterogeneous Compute with Cache Coherence

As a research computer, Enzian is designed for computer systems software research, rather than any particular commercial workload. An Enzian node has a big server-class Marvell CPU closely coupled to a large Xilinx FPGA, in cache coherence with ample main memory and network bandwidth on both sides. The team has 9 (nine!) working Enzian machines in Zurich networked and in use by researchers around the world. For more background on Enzian, including presentations at ASPLOS 2022, the 2020 Conference on Innovative Data Systems Research (CIDR), and the live demo at the 2020 IAP Workshop organized by the University of Washington University, UC Berkeley and NYU on the Future of Cloud Computing Applications and Infrastructure, please see the Enzian website.
Traditional systems software research is facing a new challenge to its relevance. Modern hardware CAD systems, the drive to lower power and "dark silicon", FPGAs, and other factors have made it easy, quick, and cheap for system vendors to build custom hardware platforms. Almost any function can now be put into silicon or reconfigurable logic: the choice of exactly what “should” be built is a short-term business decision based on markets and workloads.
Such hardware qualitatively changes how systems, including system software, should be conceived and designed. However, most published OS research in rack-scale, embedded, or datacenter computing only uses affordable commodity platforms for which documentation is available to researchers. Academia and industry practice are diverging.
Traditional systems software research is facing a new challenge to its relevance. Modern hardware CAD systems, the drive to lower power and "dark silicon", FPGAs, and other factors have made it easy, quick, and cheap for system vendors to build custom hardware platforms. Almost any function can now be put into silicon or reconfigurable logic: the choice of exactly what “should” be built is a short-term business decision based on markets and workloads.
Such hardware qualitatively changes how systems, including system software, should be conceived and designed. However, most published OS research in rack-scale, embedded, or datacenter computing only uses affordable commodity platforms for which documentation is available to researchers. Academia and industry practice are diverging.
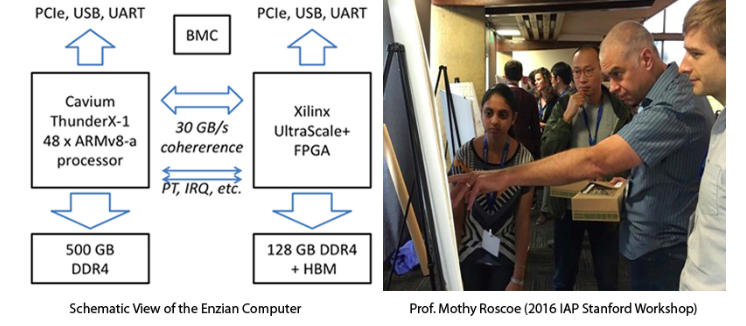
Enzian is a new research computer designed and built at ETH Zurich (with help from Marvell and Xilinx) to bridge this gap in a way not possible with commodity hardware or simulation. Enzian nodes closely couple a server-class CPU SoC with a large FPGA in the same coherence domain, with abundant network bandwidth to both chips. It is designed for maximum research flexibility, and can be used in many ways: a high-end server with FPGA-based acceleration, a multiport 200Gb/s NIC supporting custom protocols and cache access, a platform for runtime verification and auditing of system code, to name but three.
Data Center Networking
Data Center Networking

Publication: Xenic: SmartNIC-Accelerated Distributed Transactions Henry Schuh, Weihao Liang (University of Washington), Ming Liu (University of Wisconsin), Jacob Nelson (Microsoft), Arvind Krishnamurthy (University of Washington)
High-performance distributed transactions require efficient remote operations on database memory and protocol metadata. The high communication cost of this workload calls for hardware acceleration. Recent research has applied RDMA to this end, leveraging the network controller to manipulate host memory without consuming CPU cycles on the target server. However, the basic read/write RDMA primitives demand trade-o s in data structure and protocol design, limiting their benefits. SmartNICs are a flexible alternative for fast distributed transactions, adding programmable compute cores and on-board memory to the network interface. Applying measured performance characteristics, we design Xenic, a SmartNIC-optimized transaction processing system. Xenic applies an asynchronous, aggregated execution model to maximize network and core efficiency. Xenic’s co-designed data store achieves low-overhead remote object accesses. Additionally, Xenic uses flexible, point-to-point communication patterns between SmartNICs to minimize transaction commit latency. We compare Xenic against prior RDMA- and RPC-based transaction systems with the TPC- C, Retwis, and Smallbank benchmarks. Our results for the three benchmarks show 2.42×, 2.07×, and 2.21× throughput improvement, 59%, 42%, and 22% latency reduction, while saving 2.3, 8.1, and 10.1 threads per server.
This paper was presented at ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP ’21) in October 2021.
Publication: Off-loading Load Balancers onto SmartNICs Tianyi Cui, Kaiyuan Zhang (University of Washington), Wei Zhang (Microsoft), Arvind Krishnamurthy (University of Washington).
Load balancers are pervasively used inside today’s clouds to distribute network requests across data center servers at scale. While load balancers were initially built using dedicated and custom hardware, most cloud providers now use software-based load balancers. This allows the implementations to be more agile and also enables on-demand provisioning of load balancing workloads on generic servers, but it comes with increased provisioning and operating costs.
We explore off-loading load balancing onto programmable SmartNICs. To fully leverage the cost and energy efficiency of SmartNICs, our design proposes three key ideas. First, we argue that a full and complex TCP/IP stack is not required even for L7 load balancers and instead propose a design that uses a lightweight forwarding agent on the SmartNIC. Second, we develop connection management data structures that provide a high degree of concurrency with minimal synchronization when executed on multi-core SmartNICs. Finally, we describe how the load balancing logic could be accelerated using custom accelerators on SmartNICs.
This paper was presented at the ACM Asia-Pacific Workshop on Systems (APSys) 2021 in August 2021.
Publication: IncBricks: Toward In-Network Computation with an In-Network Cache Ming Liu, L. Luo, (university of Washington), Jacob Nelson (Microsoft), Luis Ceze, Arvind Krishnamurthy (University of Washington), Kishore Atreya (Marvell) - Honorable Mention for IEEE Micro Top Picks
IncBricks is an in-network caching fabric with basic computing primitives. IncBricks is a hardware-software co-designed system that supports caching in the network using a programmable network middlebox. As a key-value store accelerator, the prototype lowers request latency by over 30% and doubles throughput for 1024 byte values in a common cluster configuration.
This work was presented at the 22nd Intl. Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Xi'an, China.
High-performance distributed transactions require efficient remote operations on database memory and protocol metadata. The high communication cost of this workload calls for hardware acceleration. Recent research has applied RDMA to this end, leveraging the network controller to manipulate host memory without consuming CPU cycles on the target server. However, the basic read/write RDMA primitives demand trade-o s in data structure and protocol design, limiting their benefits. SmartNICs are a flexible alternative for fast distributed transactions, adding programmable compute cores and on-board memory to the network interface. Applying measured performance characteristics, we design Xenic, a SmartNIC-optimized transaction processing system. Xenic applies an asynchronous, aggregated execution model to maximize network and core efficiency. Xenic’s co-designed data store achieves low-overhead remote object accesses. Additionally, Xenic uses flexible, point-to-point communication patterns between SmartNICs to minimize transaction commit latency. We compare Xenic against prior RDMA- and RPC-based transaction systems with the TPC- C, Retwis, and Smallbank benchmarks. Our results for the three benchmarks show 2.42×, 2.07×, and 2.21× throughput improvement, 59%, 42%, and 22% latency reduction, while saving 2.3, 8.1, and 10.1 threads per server.
This paper was presented at ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP ’21) in October 2021.
Publication: Off-loading Load Balancers onto SmartNICs Tianyi Cui, Kaiyuan Zhang (University of Washington), Wei Zhang (Microsoft), Arvind Krishnamurthy (University of Washington).
Load balancers are pervasively used inside today’s clouds to distribute network requests across data center servers at scale. While load balancers were initially built using dedicated and custom hardware, most cloud providers now use software-based load balancers. This allows the implementations to be more agile and also enables on-demand provisioning of load balancing workloads on generic servers, but it comes with increased provisioning and operating costs.
We explore off-loading load balancing onto programmable SmartNICs. To fully leverage the cost and energy efficiency of SmartNICs, our design proposes three key ideas. First, we argue that a full and complex TCP/IP stack is not required even for L7 load balancers and instead propose a design that uses a lightweight forwarding agent on the SmartNIC. Second, we develop connection management data structures that provide a high degree of concurrency with minimal synchronization when executed on multi-core SmartNICs. Finally, we describe how the load balancing logic could be accelerated using custom accelerators on SmartNICs.
This paper was presented at the ACM Asia-Pacific Workshop on Systems (APSys) 2021 in August 2021.
Publication: IncBricks: Toward In-Network Computation with an In-Network Cache Ming Liu, L. Luo, (university of Washington), Jacob Nelson (Microsoft), Luis Ceze, Arvind Krishnamurthy (University of Washington), Kishore Atreya (Marvell) - Honorable Mention for IEEE Micro Top Picks
IncBricks is an in-network caching fabric with basic computing primitives. IncBricks is a hardware-software co-designed system that supports caching in the network using a programmable network middlebox. As a key-value store accelerator, the prototype lowers request latency by over 30% and doubles throughput for 1024 byte values in a common cluster configuration.
This work was presented at the 22nd Intl. Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Xi'an, China.

Prof. Arvind Krishnamurthy (left) describes innovations in programmable switches at the 2017 UW Cloud Workshop. The emergence of programmable network devices and the increasing data traffic of datacenters motivate the idea of in-network computation. By offloading compute operations onto intermediate networking devices (e.g., switches, net- work accelerators, middleboxes), one can (1) serve network requests on the fly with low latency; (2) reduce datacenter traffic and mitigate network congestion; and (3) save energy by running servers in a low-power mode. However, since (1) existing switch technology doesn't provide general computing capabilities, and (2) commodity datacenter networks are complex (e.g., hierarchical fat-tree topologies, multipath communication), enabling in-network computation inside a datacenter is a challenging task that IncBricks tackles.